The artificial intelligence revolution is no longer a distant future; it’s a present-day reality reshaping industries from healthcare to finance. At the heart of this transformation lies a voracious appetite for data. AI models, particularly in machine learning, are trained on vast datasets to learn patterns, make predictions, and generate insights. However, this data often contains the digital footprints of individuals—their names, addresses, financial details, and health records. This is Personally Identifiable Information (PII), and its mishandling in the complex, often opaque world of AI processing is a ticking time bomb for any organization. A single breach can lead to devastating financial penalties, irreparable reputational damage, and a complete erosion of customer trust. Therefore, establishing a robust, clear, and auditable PII handling flow for AI-enabled processes isn’t just a compliance checkbox; it’s a fundamental pillar of responsible innovation.
The Amplified Risk: PII in the Age of AI
Traditional data processing had its risks, but AI introduces new dimensions of complexity and vulnerability. The sheer volume and velocity of data required to train sophisticated models dramatically expand the potential attack surface. Furthermore, the nature of AI itself creates unique privacy challenges that legacy systems were not designed to handle.
One major concern is the “black box” nature of many advanced models, like deep neural networks. It can be incredibly difficult to trace exactly how a specific piece of PII was used to influence a model’s output, making auditing and accountability a significant hurdle. This opacity gives rise to specific AI-centric threats:
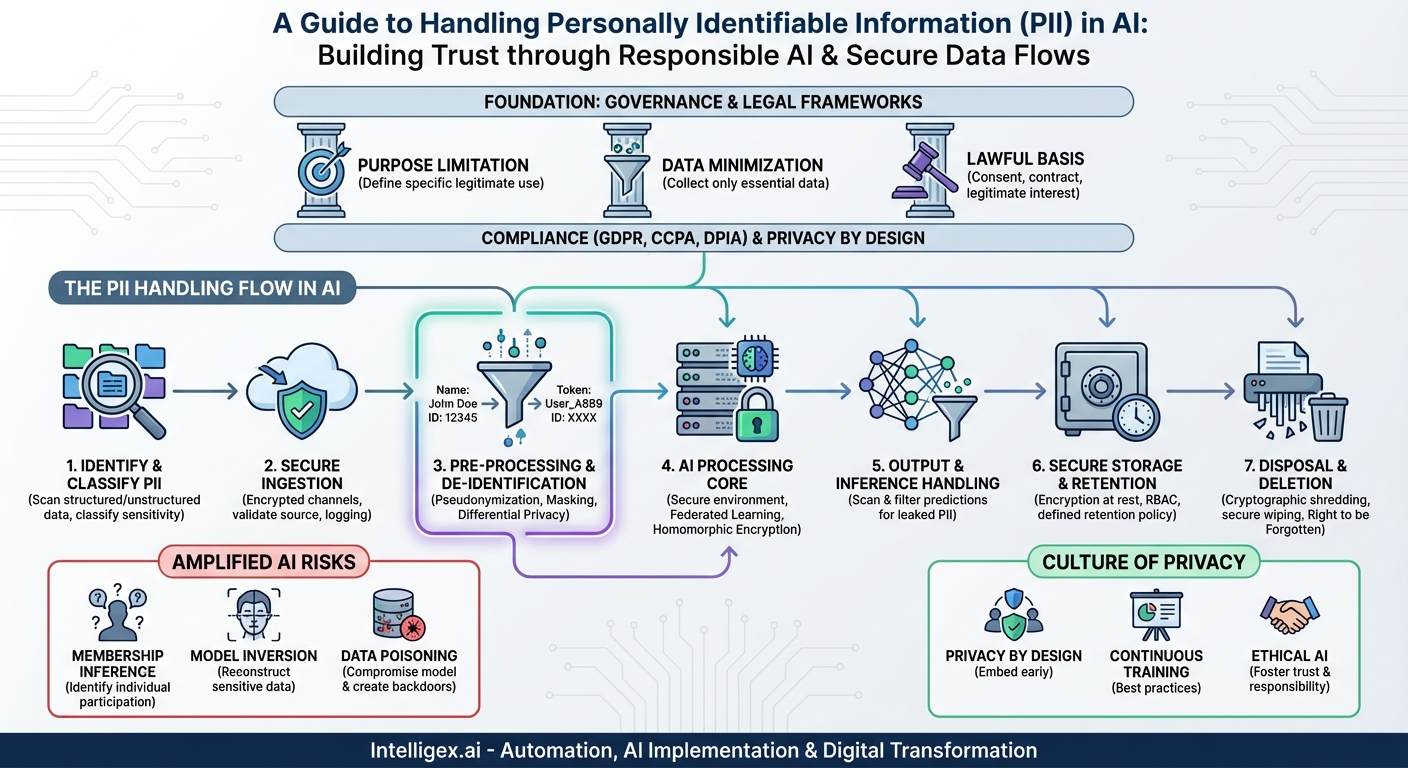
- Membership Inference Attacks: Attackers can query a model to determine whether a specific individual’s data was used in its training set, revealing sensitive information about that person’s participation (e.g., being part of a medical study).
- Model Inversion Attacks: By analyzing a model’s outputs, an attacker can potentially reconstruct parts of the sensitive data it was trained on. For example, a facial recognition model could be reverse-engineered to recreate images of faces from its training dataset.
- Data Poisoning: Malicious actors could intentionally insert tainted data into a training set, not only to compromise the model’s performance but also to create backdoors for extracting PII later on.
Without a structured flow for handling PII, these risks are not just theoretical. They represent clear and present dangers to both the individuals whose data is being used and the organizations deploying the AI.
Laying the Foundation: Governance and Legal Frameworks
Before a single byte of data enters your AI pipeline, a rock-solid foundation of data governance and legal compliance must be in place. This is the bedrock upon which a secure PII handling flow is built. Key principles here include:
- Purpose Limitation: You must clearly define and document the specific, legitimate purpose for which the PII is being collected and processed by the AI. Using data collected for customer service analytics to train an unrelated marketing model may violate this principle and privacy laws.
- Data Minimization: A cornerstone of regulations like GDPR and CCPA/CPRA, this principle dictates that you should only collect and process the PII that is absolutely necessary for your defined purpose. If the AI model can be trained effectively without knowing a user’s exact street address, that data should not be collected.
- Lawful Basis for Processing: You must identify a valid legal reason for processing PII. This is most often explicit user consent, but can also include legitimate interest, contractual necessity, or other bases depending on the jurisdiction. For AI, consent must be informed, specific, and unambiguous about how the data will be used.
Understanding the legal landscape is non-negotiable. Regulations like Europe’s GDPR, California’s CPRA, and others around the world carry significant penalties for non-compliance. These laws often include specific provisions regarding automated decision-making and profiling, making them directly applicable to many AI use cases. A thorough Data Protection Impact Assessment (DPIA) should be a mandatory step before embarking on any new AI project that involves PII.
A Step-by-Step Flow for Handling PII in AI Processes
With a strong governance framework in place, you can design a secure and efficient workflow for managing PII from initial collection to final disposal. This flow ensures that privacy and security are considered at every stage of the AI lifecycle.
Step 1: PII Identification and Classification
You can’t protect what you don’t know you have. The first step is to meticulously identify and classify PII within your datasets. This involves scanning structured data (like databases) and unstructured data (like text documents or images) to locate sensitive information. PII can be a direct identifier (e.g., name, Social Security Number) or a quasi-identifier (e.g., zip code, date of birth) that can be combined with other information to identify an individual. Once identified, data should be classified based on its sensitivity (e.g., Public, Confidential, Restricted) to determine the appropriate level of security controls.
Step 2: Secure Ingestion and Collection
Data must be collected and transferred into your systems through secure, encrypted channels (such as TLS/HTTPS or SFTP). The source of the data must be validated to ensure its integrity and legitimacy. At this stage, comprehensive logging and auditing should begin, creating a clear record of what data was received, from where, and when. This audit trail is crucial for compliance and for tracing any potential issues back to their source.
Step 3: Pre-processing and De-identification
This is arguably the most critical stage for protecting privacy in AI. Before feeding data into a model, you must apply robust de-identification techniques to minimize PII exposure. The goal is to retain the data’s utility for training the model while removing or obfuscating the sensitive parts. Key techniques include:
- Pseudonymization: Replacing direct identifiers with consistent but non-identifying tokens. This is often preferred over full anonymization because it allows for linking data points for the same individual without revealing their identity, preserving relational integrity.
- Data Masking and Redaction: Obscuring specific fields of data, for example, by replacing all but the last four digits of a credit card number with ‘X’.
- Differential Privacy: A powerful mathematical technique that involves adding carefully calibrated statistical “noise” to a dataset. This makes it impossible to determine whether any single individual’s data was part of the set, providing strong, provable privacy guarantees while still allowing for accurate aggregate analysis and model training.
Step 4: The AI Processing Core (Training & Inference)
Even with de-identified data, the processing environment itself must be secure. AI model training should occur in isolated, tightly-controlled environments with strict access controls. Only authorized personnel should be able to interact with the training data and the model-building process. For highly sensitive use cases, consider advanced privacy-enhancing technologies (PETs) like:
- Federated Learning: Instead of moving raw data to a central server, this approach sends the model to the data. The model is trained locally on decentralized devices (like mobile phones), and only the updated model parameters—not the raw PII—are sent back to the central server.
- Homomorphic Encryption: A cutting-edge cryptographic method that allows for computations to be performed directly on encrypted data. While computationally intensive, it offers the ultimate protection by ensuring the raw data is never decrypted during processing.
Step 5: Output and Inference Handling
The risk doesn’t end once the model is trained. The outputs generated by an AI model (its predictions or generated content) can inadvertently leak PII it learned from the training data. For instance, a large language model trained on a corpus of emails might accidentally output a real person’s name and phone number in response to a prompt. Therefore, all model outputs must be rigorously scanned and filtered for potential PII before being displayed to a user or stored in a log.
Step 6: Secure Storage and Retention
All data associated with the AI process—the raw data, the processed data, the trained models, and the output logs—must be stored securely. This means enforcing encryption at rest for all stored artifacts. Access should be governed by strict Role-Based Access Control (RBAC) to ensure only authorized individuals can access sensitive information. Crucially, you must establish and enforce a clear data retention policy. How long will you keep the training data? How long are models retained? These policies must align with legal requirements and the original purpose of data collection, and data should be purged automatically once it is no longer needed.
Step 7: Disposal and Deletion
When data reaches the end of its lifecycle, it must be disposed of securely and permanently. This involves more than just clicking ‘delete’. Secure deletion protocols, such as cryptographic shredding (deleting the encryption keys) or multi-pass data wiping, should be used. This process must also account for backups and archives. Furthermore, data privacy laws like GDPR grant individuals the “Right to be Forgotten.” Your organization must have a clear process for honouring these requests, which presents a unique challenge for AI. It can be difficult or impossible to “remove” a single person’s influence from a massive, already-trained model. This complexity underscores the importance of robust de-identification at the start of the process.
Fostering a Culture of Privacy-Aware AI Development
A technical workflow is only as strong as the people who implement and follow it. Technology alone cannot solve the PII challenge; a cultural shift is required. Organizations must champion the concept of Privacy by Design, embedding privacy considerations into the AI development lifecycle from the very first brainstorming session, not as a last-minute compliance check.
Privacy is not an afterthought; it is a core requirement for building trustworthy and sustainable AI systems. It must be woven into the fabric of your data strategy and engineering culture.
This involves continuous training for data scientists, engineers, and product managers on PII handling best practices and the ethical implications of their work. Regular internal audits and third-party assessments of your AI systems can help identify vulnerabilities before they become breaches. Fostering an environment where engineers feel empowered to raise privacy concerns is vital for creating systems that are not only powerful but also respectful of the individuals whose data they leverage.
Ultimately, navigating the complexities of PII in an AI-driven world is a journey of responsibility. By implementing a comprehensive handling flow—from foundational governance to secure disposal—and fostering a culture of privacy, organizations can do more than just avoid penalties. They can build innovative, powerful AI solutions that earn the most valuable asset of all: public trust. This is the path to unlocking the true potential of artificial intelligence, safely and ethically.
Related Posts
Category:
Get a FREE
Proof of Concept
& Consultation
No Cost, No Commitment!