Artificial intelligence is no longer a futuristic concept; it’s a core component of modern business, driving everything from customer service chatbots to complex financial modeling and medical diagnoses. As organizations rush to deploy AI and machine learning (ML) models into production, they are inadvertently creating a new and highly complex attack surface. Traditional cybersecurity measures, designed for deterministic software, often fall short when faced with the probabilistic and data-dependent nature of AI systems. Securing AI isn’t about simply placing a firewall around a model; it requires a fundamental shift in thinking.
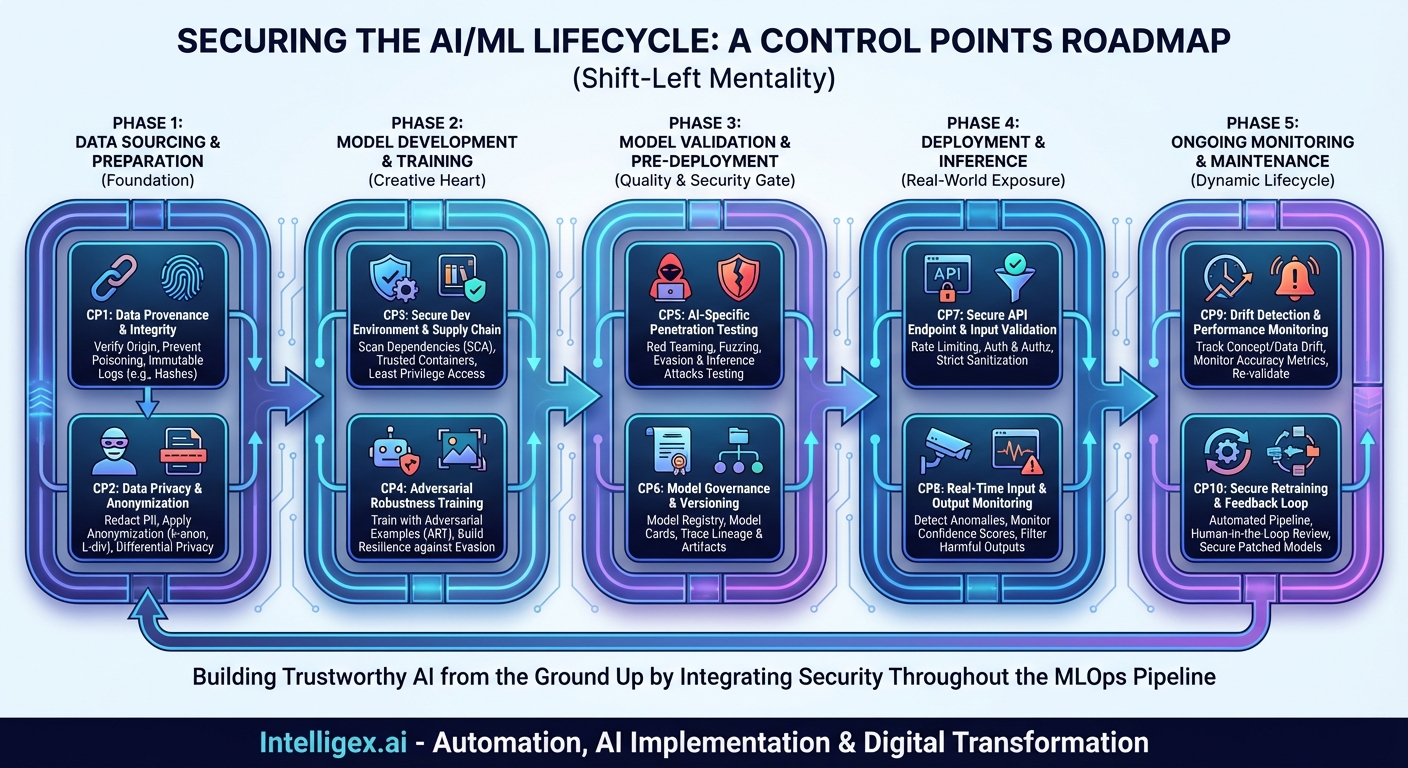
To truly secure an AI deployment, we must adopt a “shift-left” mentality, integrating security controls throughout the entire machine learning lifecycle. This requires a new kind of roadmap: a Control Points Map. This map identifies the critical junctures from data acquisition to post-deployment monitoring where vulnerabilities can arise and where specific security controls must be implemented. By treating the AI lifecycle as a supply chain, we can fortify each link, building a resilient and trustworthy system from the ground up.
This post will walk you through this map, detailing the key control points across the five major phases of AI deployment. Think of this as your strategic guide to navigating the complex terrain of AI security.
Phase 1: Data Sourcing & Preparation
The foundation of any AI model is its data. If the foundation is compromised, the entire structure is unstable. Attacks at this stage are subtle, potent, and incredibly difficult to detect later in the process. Therefore, the first phase of our map focuses on the sanctity of your data.
Control Point 1: Data Provenance and Integrity
What It Is: This control is about ensuring you know exactly where your data comes from (provenance) and that it has not been altered or tampered with since its creation (integrity). It’s the digital chain of custody for your most critical asset.
Why It Matters: The primary threat here is data poisoning. An attacker could subtly manipulate the training data—for example, by mislabeling a small fraction of images of “stop signs” as “speed limit signs.” A model trained on this poisoned data will be fundamentally flawed, creating a built-in backdoor that can be exploited later. Without strong provenance and integrity checks, you have no way of trusting your data source.
How to Implement:
- Use cryptographic hashes (e.g., SHA-256) to create a fingerprint of datasets at each stage of the pipeline.
- Employ digital signatures to verify the origin of data from third-party suppliers.
- Maintain immutable audit logs of all transformations and accesses to the raw data.
- Whenever possible, use data from trusted, well-vetted sources and repositories.
Control Point 2: Data Privacy and Anonymization
What It Is: This involves identifying and protecting personally identifiable information (PII) and other sensitive data within your datasets. It’s not just about compliance; it’s about reducing the model’s potential to leak sensitive information.
Why It Matters: Models can inadvertently memorize parts of their training data. An attacker could use membership inference attacks to determine if a specific individual’s data was part of the training set, or even use model inversion attacks to reconstruct sensitive data points. Beyond the direct security risk, failure to protect data can lead to severe regulatory fines under laws like GDPR and CCPA.
How to Implement:
- Utilize PII scanning tools to automatically detect and redact sensitive information.
- Apply anonymization techniques like k-anonymity or l-diversity.
- For maximum protection, implement differential privacy, a formal mathematical framework that adds statistical noise to data to make it impossible to identify individuals while preserving overall statistical patterns.
- Consider using high-quality synthetic data for initial development to minimize exposure of real data.
Phase 2: Model Development & Training
This is the creative heart of the AI lifecycle, where data scientists and ML engineers build and train the model. It’s also a phase ripe with opportunities for introducing vulnerabilities through insecure code, compromised dependencies, or flawed training methodologies.
Control Point 3: Secure Development Environment & Supply Chain
What It Is: This control point focuses on securing the tools, libraries, and platforms used to build the model. It extends traditional DevSecOps principles to the MLOps pipeline.
Why It Matters: The AI development ecosystem relies heavily on open-source libraries (like TensorFlow, PyTorch, scikit-learn). A compromised library—a software supply chain attack—could inject malicious code into your model, steal data, or create hidden vulnerabilities. An insecure development notebook could also expose credentials or proprietary algorithms.
How to Implement:
- Use Software Composition Analysis (SCA) tools to scan for known vulnerabilities in all dependencies.
- Enforce the use of trusted, internally vetted container images for development and training environments.
- Apply the principle of least privilege to data access within development platforms. A data scientist training a recommendation engine shouldn’t have access to raw financial data.
- Scan code and configuration files for hardcoded secrets and credentials.
Control Point 4: Adversarial Robustness Training
What It Is: This is a proactive defense mechanism where the model is intentionally trained on data designed to fool it. It’s like an immune system being exposed to a weakened virus to build resistance.
Why It Matters: AI models, particularly in computer vision, are vulnerable to evasion attacks. An attacker can make tiny, often human-imperceptible changes to an input to cause a misclassification. For example, adding a small, specially crafted sticker to a stop sign could make an autonomous vehicle’s model classify it as a green light. Adversarial training makes the model more resilient to these kinds of perturbations.
How to Implement:
- Use frameworks like the Adversarial Robustness Toolbox (ART) to generate adversarial examples.
- Incorporate these generated examples into your training dataset, correctly labeled, to teach the model to ignore adversarial noise.
- Explore techniques like defensive distillation, which involves training a second model on the probability outputs of a first model to create a smoother, more robust decision boundary.
Phase 3: Model Validation & Pre-Deployment
Before a model is released into the wild, it must undergo rigorous testing that goes beyond standard accuracy metrics. This phase is the quality assurance and security gate for your AI system.
Control Point 5: AI-Specific Penetration Testing
What It Is: This involves forming a “red team” to actively attack the model before it’s deployed. This team simulates real-world attack techniques to discover vulnerabilities that standard validation might miss.
Why It Matters: Standard performance metrics (accuracy, precision, recall) do not measure security. A model can be 99% accurate on a test set but still be trivially easy to fool with an evasion attack. AI red teaming specifically tests for security flaws like evasion, model extraction (stealing the model), and data privacy vulnerabilities.
How to Implement:
- Conduct structured fuzzing, feeding the model malformed or unexpected inputs to test its stability.
- Attempt various evasion attacks using both white-box (with knowledge of the model architecture) and black-box (querying the API only) methods.
- Perform membership inference and model inversion tests to assess data leakage risks.
- Document all findings and ensure they are remediated before deployment, likely by retraining the model with new defenses.
Control Point 6: Model Governance and Versioning
What It Is: This is the practice of maintaining a secure, auditable, and immutable record of every model, the data it was trained on, its hyperparameters, and its performance metrics.
Why It Matters: If a vulnerability is discovered in a production model, you need a reliable way to roll back to a previously known-good version. Proper governance ensures you can trace a model’s lineage, understand its components, and satisfy regulatory and audit requirements. It is a cornerstone of responsible and secure AI.
How to Implement:
- Use a dedicated Model Registry (e.g., MLflow, SageMaker Model Registry) to store versioned model artifacts.
- Generate a “model card” or “AI factsheet” for each version, documenting its intended use, limitations, training data, and fairness metrics.
- Integrate the model registry with your CI/CD pipeline to automate the deployment of approved models.
Phase 4: Deployment & Inference
Once the model is live, it’s exposed to real-world traffic and potential threats. The focus here shifts to protecting the inference endpoint and monitoring its behavior in real-time.
Control Point 7: Secure API Endpoint and Input Validation
What It Is: This involves wrapping the model in a hardened API and applying traditional application security best practices.
Why It Matters: The API is the front door to your model. Without proper security, it can be subjected to denial-of-service attacks, unauthorized access, or query-based attacks where an attacker can infer information about the model or its data by sending a large volume of queries.
How to Implement:
- Enforce strong authentication and authorization to control who can access the model.
- Implement rate limiting to prevent brute-force queries and model extraction attempts.
- Apply rigorous input validation and sanitization. For example, if your model expects a JPEG image, the API should reject all other file types to prevent attacks that exploit file parsers.
Control Point 8: Real-Time Input and Output Monitoring
What It Is: This is the active surveillance of the data flowing into and out of the production model. It acts as an intrusion detection system specifically for AI.
Why It Matters: This is your first line of defense against zero-day evasion attacks. By monitoring the statistical distribution of input data, you can detect when an attacker is sending inputs that are significantly different from the training data—a hallmark of an adversarial attack. Monitoring outputs for low-confidence predictions or unusual patterns can also signal that the model is being targeted or is behaving unexpectedly.
How to Implement:
- Establish a baseline of normal input data characteristics and alert on significant deviations.
- Log all predictions and their confidence scores. Flag sustained periods of low-confidence predictions for review.
- Implement an output filter to catch or quarantine nonsensical or potentially harmful responses, especially for generative AI models.
Phase 5: Ongoing Monitoring & Maintenance
An AI model is not a static piece of software. It exists in a dynamic environment where data distributions change and new threats emerge. Security must be an ongoing process.
Control Point 9: Drift Detection and Performance Monitoring
What It Is: This involves continuously tracking the model’s performance on live data to detect “drift”—a degradation in accuracy over time.
Why It Matters: Drift can occur naturally as the real world changes (concept drift), or it can be a sign of a subtle, ongoing attack. For example, an attacker could slowly feed the model biased data to push its decision boundary in a preferred direction. Monitoring for drift is crucial for knowing when a model is no longer reliable or is potentially under attack.
How to Implement:
- Continuously compare the statistical properties of live data against the training data.
- Track key performance metrics (accuracy, F1-score, etc.) over time and set up automated alerts for significant drops.
- Use a “golden dataset” of labeled, representative data to periodically re-validate the model’s performance.
Control Point 10: Secure Retraining and Feedback Loop
What It Is: This is the process of having a secure, automated pipeline to update and redeploy the model with new data or improved architecture.
Why It Matters: When drift is detected or a new vulnerability is discovered, you need to be able to respond quickly. A secure MLOps pipeline allows you to retrain, re-validate, and redeploy a patched model with minimal downtime. It closes the loop, turning insights from production monitoring into a more resilient next-generation model.
How to Implement:
- Automate the retraining pipeline, triggered by drift detection alerts or a regular schedule.
- Ensure that any new data collected from production for retraining goes through the same rigorous integrity and privacy checks (Control Points 1 & 2) as the original data.
- Implement a human-in-the-loop review process for flagged predictions, creating a curated dataset for fine-tuning the model against observed attacks.
Conclusion: Building a Culture of AI Security
The journey to secure AI is not about implementing a single tool or a one-time check. It’s about embedding security into the very fabric of the MLOps lifecycle. The Control Points Map provides a framework for this journey, transforming security from an afterthought into a foundational principle.
By systematically addressing the risks at each stage—from the integrity of the initial data to the continuous monitoring of the deployed model—organizations can move beyond building powerful AI to building trustworthy AI. In a world increasingly reliant on automated decision-making, that trust is not just a feature; it is the ultimate currency.
Your Next Read:
Category:
Get a FREE
Proof of Concept
& Consultation
No Cost, No Commitment!