Artificial intelligence is no longer a futuristic concept discussed in boardrooms; it has become the silent, operational backbone of modern business. From dynamic pricing engines and automated customer support to predictive maintenance and sophisticated fraud detection, AI-powered workflows are deeply embedded in the processes that drive revenue and create value. This integration has unlocked unprecedented efficiency and innovation. However, it has also introduced a new, complex, and often misunderstood category of operational risk. When a traditional software application fails, the contingency plans are usually well-understood. But what happens when your AI model—the very “brain” of a critical workflow—goes offline, starts to degrade, or produces harmful outputs? The consequences can be immediate and severe, impacting everything from customer trust to your bottom line. Traditional Business Continuity Plans (BCPs), designed for infrastructure outages and data loss, are ill-equipped to handle the unique failure modes of AI. It’s time to evolve our approach to resilience by developing a dedicated Business Continuity Plan specifically for our AI-dependent workflows.
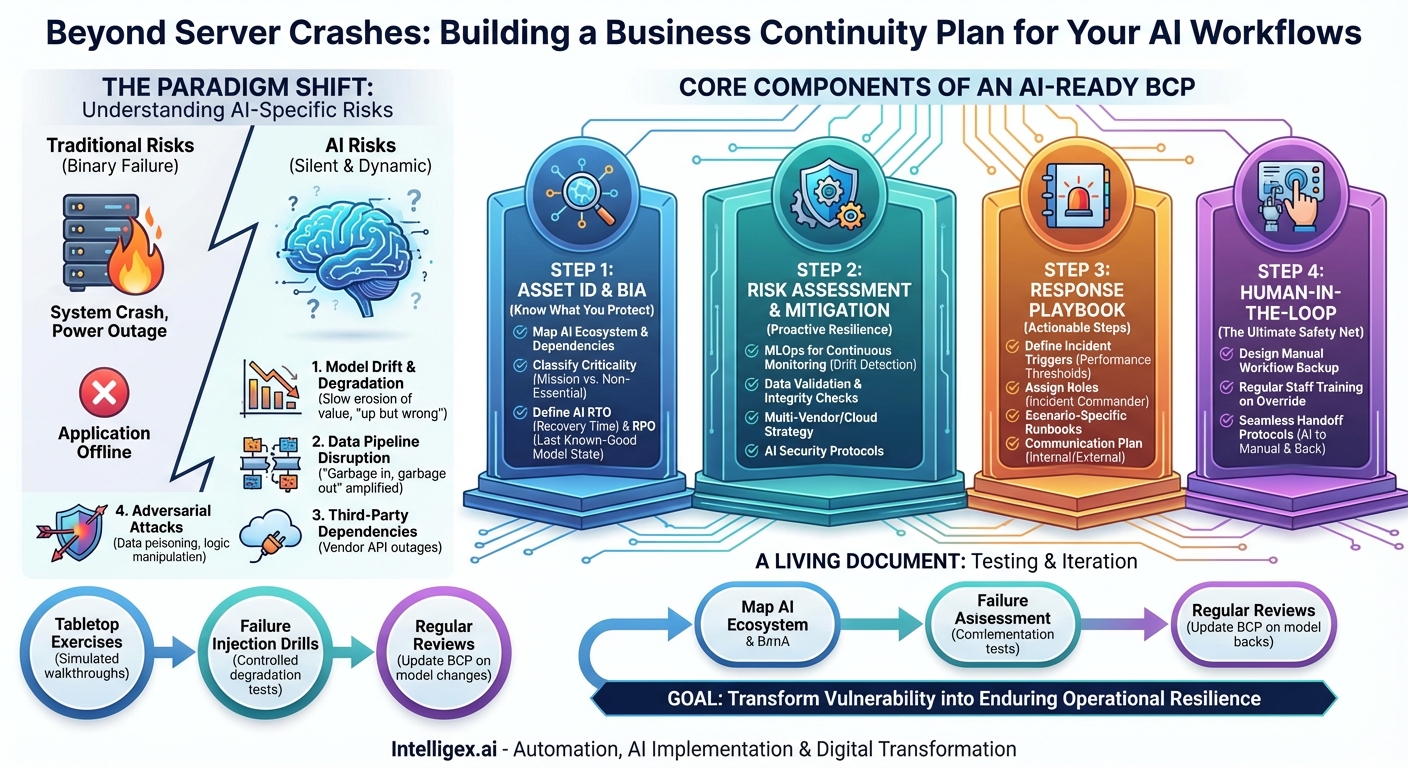
The New Landscape of AI-Specific Risks
Before building a plan, we must first understand the unique nature of the threats. AI systems are not static software; they are dynamic, data-driven entities that can fail in ways that are far more subtle and insidious than a simple server crash. A robust AI BCP must account for a spectrum of potential disruptions that go beyond simple availability.
1. Model Performance Degradation and Drift
Perhaps the most common and dangerous AI-specific risk is “model drift.” This occurs when the statistical properties of the live data the model sees in production begin to differ from the data it was trained on. The world changes, but the model doesn’t, causing its accuracy and effectiveness to silently decay over time. A customer recommendation engine might start suggesting irrelevant products, or a credit scoring model could begin unfairly penalizing a new demographic. This isn’t a crash; it’s a slow, quiet erosion of value and a potential source of significant reputational damage. The system is “up,” but it’s wrong.
2. Data Pipeline Disruption or Corruption
AI models are fundamentally powered by data. The principle of “garbage in, garbage out” is amplified exponentially in AI workflows. A disruption to your data pipeline—whether from a broken ETL process, a corrupted data source, or a change in a third-party API format—can have immediate and catastrophic effects on the model’s output. Your AI is only as reliable as the data feeding it. A BCP must therefore extend beyond the model itself to encompass the entire data ecosystem that supports it.
3. Third-Party and API Dependencies
Many organizations don’t build every AI component from scratch. They rely on third-party AI services, such as large language models (LLMs) via API calls, cloud-based machine learning platforms, or specialized data providers. This creates a significant external dependency. An outage at your cloud provider or a change in your API vendor’s terms of service can bring your critical workflow to a screeching halt. Your continuity plan is now tied to the reliability and business decisions of your vendors, making vendor risk management a critical component of your AI BCP.
4. Adversarial Attacks and Security Vulnerabilities
AI models introduce novel security attack surfaces. Malicious actors can attempt to “poison” the training data to create hidden backdoors or manipulate input data in subtle ways to trick the model into making a specific, incorrect prediction. For example, a fraud detection system could be deliberately tricked into approving a fraudulent transaction. These are not traditional hacks; they are sophisticated attacks on the logic of the model itself, requiring a new paradigm of security monitoring and response.
Core Components of an AI-Ready BCP
Building a BCP for AI workflows requires a structured approach that mirrors traditional continuity planning but adapts each phase for the nuances of artificial intelligence. It’s a cycle of identification, mitigation, response, and iteration.
Step 1: Asset Identification and Business Impact Analysis (BIA)
You cannot protect what you don’t know you have. The first step is to conduct a thorough inventory of every AI and machine learning model integrated into your business processes.
- Map Your AI Ecosystem: Create a comprehensive registry of all AI models in production. For each model, document its purpose, the business workflow it supports, its data sources, its owners (both business and technical), and its dependencies (e.g., APIs, specific libraries, cloud services).
- Classify by Criticality: Not all AI workflows are created equal. Classify each system based on its impact on the business. A model that optimizes internal reporting is less critical than one that powers your e-commerce checkout process. Use tiers like “Mission-Critical,” “Business-Critical,” and “Non-Essential.”
- Define AI-Specific RTO and RPO: Adapt the classic BCP metrics for AI.
- Recovery Time Objective (RTO): How quickly must this AI workflow be restored to an acceptable level of performance after a failure? This might not mean fully “online,” but perhaps operating via a manual backup.
- Recovery Point Objective (RPO): This is trickier for AI. It’s less about data loss and more about “model state.” What is the last known-good version of the model and its training data that you can revert to if the current one becomes corrupted or performs poorly?
Step 2: Risk Assessment and Mitigation Strategies
For each critical AI asset identified, perform a risk assessment tailored to the threats mentioned earlier. Then, develop proactive mitigation strategies to reduce the likelihood and impact of these risks.
Your goal is not just to plan for failure, but to build a system so resilient that failure is less likely to occur in the first place.
- For Model Drift: Implement robust MLOps (Machine Learning Operations) practices. This includes continuous monitoring of model accuracy, data distribution, and output predictions. Set up automated alerts for performance degradation and have a pre-defined pipeline for rapid retraining and redeployment of the model on new data.
- For Data Disruption: Build data validation and integrity checks directly into your data pipelines. Implement anomaly detection to flag sudden changes in input data volume or structure before it can poison your model’s outputs.
- For Vendor Lock-in: For mission-critical functions, explore a multi-vendor or multi-cloud strategy. Have a secondary, pre-vetted AI service provider as a backup. Abstract your code so that switching between vendors is as seamless as possible. At a minimum, have a clear understanding of your vendor’s own BCP and SLAs.
- For Security Risks: Work with your cybersecurity team to implement AI-specific security protocols. This includes securing data pipelines, controlling access to model training environments, and exploring tools that can detect adversarial input manipulation.
Step 3: The Response & Recovery Playbook
When an incident occurs, your team needs a clear, actionable playbook, not a theoretical document. This playbook should define the “who, what, and when” of your response.
- Define Incident Triggers: What constitutes an “AI incident”? It’s not just a system being offline. Define clear thresholds for performance degradation (e.g., “if model accuracy drops below 95% for more than one hour”) or data anomalies that automatically trigger the response plan.
- Establish Roles and Responsibilities: Who is the AI Incident Commander? Who is responsible for communicating with stakeholders? Who has the authority to trigger the manual override or roll back a model deployment? A clear chain of command is essential to avoid confusion during a crisis.
- Develop Scenario-Specific Runbooks: Create step-by-step instructions for different failure scenarios. For example:
- Runbook 1: Sudden Performance Drop. Steps: 1. Alert on-call data scientist. 2. Route traffic to a last known-good model version. 3. Analyze input data for anomalies. 4. Begin emergency retraining process.
- Runbook 2: Third-Party API Outage. Steps: 1. Confirm outage via vendor status page. 2. Trigger the manual backup workflow. 3. Post a notice on the customer-facing portal. 4. Continuously poll the API for recovery.
- Create a Communication Plan: How will you communicate the issue internally to your support, sales, and leadership teams? How will you communicate externally to customers who may be impacted by a faulty recommendation or a service outage? Transparency is key to maintaining trust.
Step 4: The Human-in-the-Loop: The Manual Override
For your most critical AI workflows, the ultimate safety net is a well-designed manual process. This is the non-negotiable, analog backup that ensures your business can continue to operate even if the entire AI system fails. This cannot be an afterthought; it must be designed, documented, and practiced.
- Design the Manual Workflow: What does the process look like without AI? Does a human team take over customer support chats? Does the logistics team revert to a static routing plan? Does the marketing team use a rules-based system for ad bidding?
- Train Your People: The staff responsible for executing the manual override must be regularly trained on the process. They need to know how to access the necessary tools and data and how to perform the task efficiently.
- Plan for a Seamless Handoff: Document the process for both switching to manual and, just as importantly, switching back to the AI once it’s restored. How do you reconcile data that was generated manually with the automated system to ensure consistency?
A Living Document: Testing, Review, and Iteration
A Business Continuity Plan that sits on a shelf is useless. The dynamic nature of AI demands that your BCP be a living, breathing document. Regular testing is the only way to ensure it will work when you need it most.
- Tabletop Exercises: Gather the key stakeholders in a room and walk through a simulated AI failure scenario. Talk through the playbook. Does everyone know their role? Are there gaps in the plan?
- Failure Injection and Drills: For less critical systems, consider controlled “fire drills.” Intentionally degrade a model’s performance in a staging environment to see if your monitoring systems catch it and if the team follows the runbook correctly.
- Regular Reviews: Schedule quarterly or semi-annual reviews of the AI BCP. Every time a new model is deployed or a major change is made to an existing one, the BCP must be updated to reflect the new reality.
Integrating AI into the core of your business is a strategic imperative for growth and competitiveness. But with great power comes great responsibility. Proactively planning for the failure of these complex systems is not a sign of pessimism; it is a hallmark of operational maturity and strategic foresight. By treating your AI workflows with the same diligence and rigor as any other piece of critical infrastructure, you transform a potential vulnerability into a source of enduring business resilience. The time to build your AI Business Continuity Plan is now—before a silent failure becomes a very loud crisis.
Your Next Read:
Category:
Get a FREE
Proof of Concept
& Consultation
No Cost, No Commitment!