In our hyper-connected digital landscape, system integration is no longer a luxury—it’s the central nervous system of a modern enterprise. It’s the invisible magic that allows your CRM to talk to your ERP, your marketing automation platform to sync with your sales pipeline, and your e-commerce site to update your inventory in real-time. When it works, the result is a seamless flow of data that drives efficiency, unlocks insights, and creates a superior customer experience. But when it fails, it doesn’t just create a technical glitch; it creates organizational chaos, erodes trust in data, and can bring critical business processes to a grinding halt.
The challenge is that integration is inherently complex. We’re not just connecting two applications; we’re bridging disparate technologies, data models, security protocols, and often, different organizational cultures and priorities. This complexity gives rise to a set of recurring problems that can doom a project before it ever delivers value. Understanding these common integration failure patterns is the first step toward building robust, resilient, and valuable connections between your systems. By diagnosing the symptoms, we can prescribe the right prevention tactics to ensure your integrations become a source of strength, not a constant source of frustration.
The Anatomy of Integration Complexity
Before diving into the patterns of failure, it’s crucial to appreciate why integrations are so notoriously difficult to get right. At its core, an integration project is an exercise in managing dependencies. You are making System A dependent on System B, and vice-versa. This immediately introduces several risk factors:
- Technical Diversity: Systems are often built with different programming languages, run on different infrastructures (cloud, on-premise), and expose data through a variety of mechanisms, from modern REST APIs to legacy file drops and direct database access.
- Semantic Mismatches: The concept of a “customer” might mean one thing in your sales CRM (a potential lead) and something entirely different in your finance ERP (a billed entity). Reconciling these semantic differences is a major source of integration headaches.
- Constant Change: The digital world doesn’t stand still. The systems you connect are constantly being updated with new features, patched for security, and have their data models evolved. An integration built for today’s versions might break with tomorrow’s updates.
- Hidden Dependencies: The two systems you’re connecting often have their own downstream dependencies. A slowdown in one system can cause a cascading performance issue that impacts services you didn’t even know were related.
It’s within this complex and dynamic environment that common failure patterns emerge. These aren’t just simple bugs; they are architectural and procedural anti-patterns that create systemic weaknesses.
Common Integration Failure Patterns
Over years of building and fixing integrations, the same problems tend to appear in different guises. Recognizing them is key to avoiding them in your own projects. Here are five of the most destructive patterns.
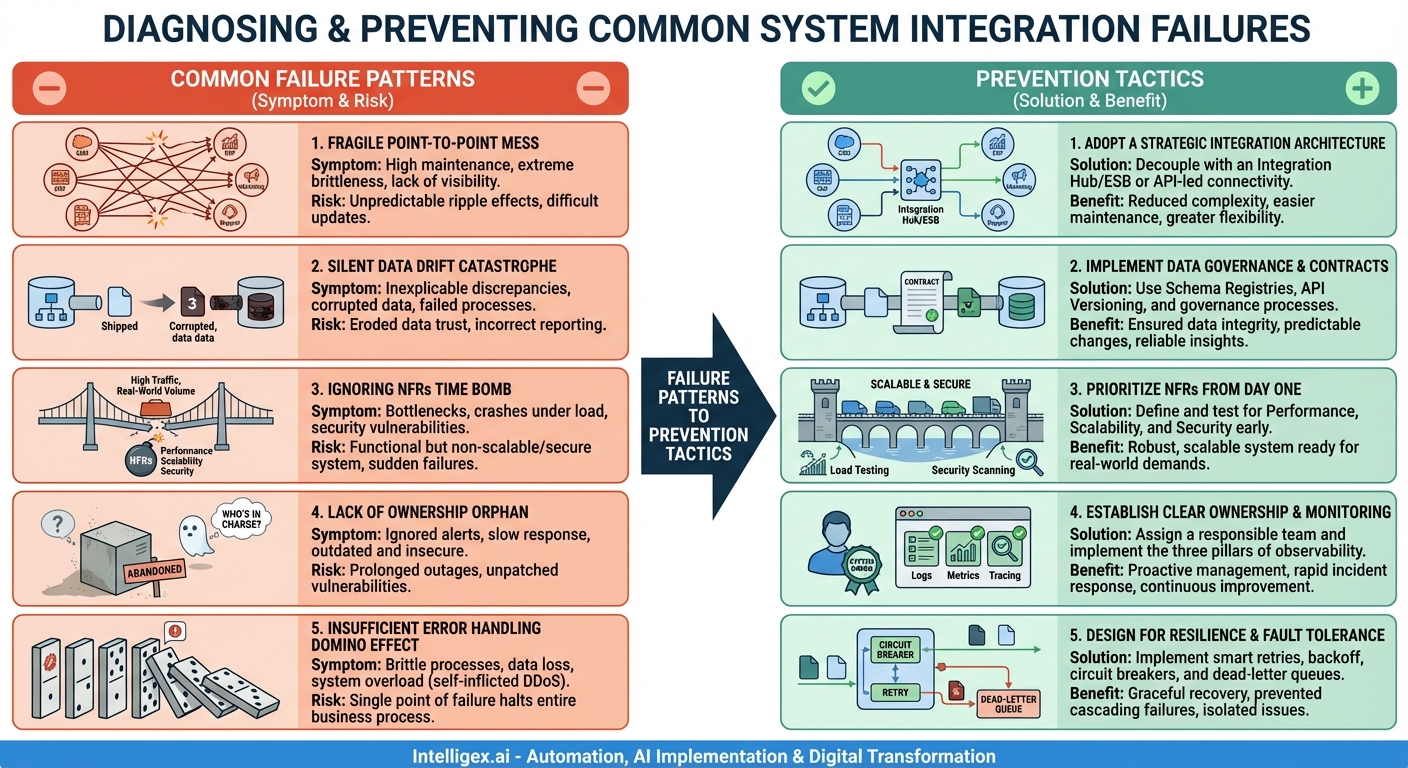
Pattern 1: The “Fragile Point-to-Point” Mess
This is perhaps the most common anti-pattern, especially in organizations that have grown organically over time. It starts with a simple need: “We just need to get customer data from the CRM into the billing system.” A developer writes a script, a direct connection is made, and the problem is solved. Then, the marketing platform needs that same customer data. Then the support tool. Soon, you have a tangled, spiderweb-like architecture where every system is directly connected to every other system it needs to talk to.
Symptoms:
- High Maintenance Overhead: A small change in one system’s API or data format requires updating every single system connected to it. The development team is constantly bogged down with maintenance.
- Lack of Visibility: There’s no central place to see the health of your integrations. Troubleshooting a failed data sync involves digging through logs on multiple different systems.
- Extreme Brittleness: The entire “architecture” is incredibly fragile. The failure of one connection can have unpredictable ripple effects, and adding a new system is a monumental task.
Pattern 2: The “Silent Data Drift” Catastrophe
This failure is insidious because it often goes unnoticed until it’s caused significant damage. It occurs when the schema or meaning (semantics) of data in one system changes without a corresponding update in the integration logic. For example, a “status” field in an order management system is changed from a string (“Shipped”) to a numeric code (3). The integration, however, still expects a string. It might fail outright, or worse, it might silently insert `null` or incorrect data into the downstream system.
Symptoms:
- Inexplicable Data Discrepancies: Reports from different systems don’t match up. The sales team sees 100 new customers, but the finance team only sees 80.
- Corrupted Data: Data in the target system becomes progressively polluted with incorrect or incomplete information, eroding user trust.
- Failed Business Processes: Automated processes that rely on the integrated data start failing without an obvious cause, leading to manual workarounds and customer-facing errors.
Pattern 3: The “Ignoring Non-Functional Requirements” Time Bomb
Many integration projects focus exclusively on making the data flow correctly in a pristine development environment. The logic is perfect, the mapping is correct, and it works flawlessly with ten test records. The project is declared a success and deployed to production. Then, reality hits. The integration crumbles under the weight of real-world transaction volumes, network latency, and security demands.
A functional integration that cannot scale is, for all practical purposes, a non-functional integration.
Symptoms:
- Performance Bottlenecks: The integration is painfully slow during peak business hours, causing timeouts and unacceptable delays in critical processes.
- Scalability Issues: It cannot handle a sudden spike in traffic (like a Black Friday sale), leading to system crashes or data loss.
- Security Vulnerabilities: Sensitive data is transmitted without proper encryption, or authentication keys are hard-coded, creating a massive security risk.
Pattern 4: The “Lack of Ownership” Orphan
The integration is built by a project team. The project ends, the team disbands and moves on to the next shiny object, and the integration is left to run in production. But who is responsible for it? Who monitors it for errors? Who applies security patches? Who manages the API keys and credentials? When the answer is “nobody” or “everybody” (which means nobody), the integration becomes an orphan.
Symptoms:
- “Alert Fatigue” or No Alerts at All: Errors are either ignored because no one feels responsible, or monitoring is so poor that no one is even aware the integration is failing.
- Slow Incident Response: When a failure is finally noticed (usually by an angry business user), there’s a frantic scramble to figure out who can fix it, leading to prolonged outages.
- Outdated and Insecure: The integration continues to run on old libraries with known vulnerabilities because no one is tasked with its upkeep.
Pattern 5: The “Insufficient Error Handling” Domino Effect
This pattern occurs when developers adopt a “happy path” mentality, assuming that network connections will always be available and data will always be perfectly formed. The integration logic doesn’t account for transient glitches (like a brief network outage) or permanent failures (like a malformed message). A single, minor error can trigger a catastrophic failure that cascades through multiple systems.
Symptoms:
- Brittle Processes: A single failed API call halts an entire multi-step business process, requiring manual cleanup and restart.
- Data Loss: If an API call fails and there’s no retry mechanism, the data may be lost forever.
- System Overload: A naive retry loop that immediately re-sends a failing request can overwhelm a struggling downstream system, turning a temporary issue into a full-blown outage (a self-inflicted DDoS attack).
Prevention Tactics: Building Resilient Integrations
Recognizing the patterns is half the battle. The other half is implementing the right architectural and procedural safeguards. These tactics are designed to directly counteract the failure patterns described above.
Tactic 1: Adopt a Strategic Integration Architecture
This is the direct antidote to the “Fragile Point-to-Point” Mess. Instead of direct connections, introduce a dedicated integration layer or middleware. This can take several forms:
Decouple with an Integration Hub or ESB
An Enterprise Service Bus (ESB) or a modern integration Platform as a Service (iPaaS) acts as a central hub. Systems publish messages to the hub, and the hub is responsible for transforming and routing them to the appropriate subscribers. This decouples the systems; the CRM no longer needs to know the specific details of the ERP’s API. It just sends a “New Customer” event to the hub.
Embrace API-Led Connectivity
This modern approach organizes APIs into three layers: System APIs (unlocking data from core systems), Process APIs (orchestrating data and processes), and Experience APIs (formatting data for specific end-user applications). This layered approach promotes reuse and isolates changes, preventing the spiderweb effect.
Tactic 2: Implement Data Governance and Contract-Based Design
To prevent “Silent Data Drift,” you must treat the structure and meaning of your data with the same discipline as your code. This means establishing clear “data contracts” between systems.
Use Schema Registries and API Versioning
For event-driven integrations (e.g., using Kafka), a schema registry (like Confluent Schema Registry) enforces data contracts. It ensures that data producers and consumers agree on the structure of the data. For API-based integrations, use strict API versioning (e.g., `/api/v2/customers`). Never make a breaking change to an existing version; instead, release a new version and provide a clear deprecation path for the old one.
Establish a Governance Process
Changes to a system’s core data model should not happen in a vacuum. A simple governance process—even just a mandatory review by the integration team—can ensure that the downstream impact of a change is considered *before* it’s implemented.
Tactic 3: Prioritize Non-Functional Requirements (NFRs) from Day One
To defuse the “Ignoring NFRs” Time Bomb, you must treat performance, scalability, and security as first-class citizens of your integration project, not as afterthoughts.
Define and Test for NFRs
At the start of the project, explicitly define the NFRs. What is the expected transaction volume? What is the maximum acceptable latency? What are the data encryption standards? These should be written down and become part of the acceptance criteria. Then, use tools for load testing (like k6 or JMeter) and security scanning to validate that the integration meets these requirements before it ever sees production traffic.
Tactic 4: Establish Clear Ownership and Comprehensive Monitoring
To save an integration from becoming a “Lack of Ownership” Orphan, you must assign clear responsibility and give that owner the tools they need to succeed.
Assign a “System Owner”
Every integration should have a named owner or a responsible team. This team is accountable for the integration’s health, maintenance, and lifecycle. They are the first point of contact when something goes wrong.
Implement the Three Pillars of Observability
Equip the owner with robust monitoring and alerting. This goes beyond simple up/down checks and includes:
- Logging: Structured logs that provide context for every transaction.
- Metrics: Dashboards tracking key performance indicators like throughput, error rate, and latency.
- Tracing: The ability to follow a single request as it travels across multiple systems to pinpoint bottlenecks.
Tactic 5: Design for Resilience and Fault Tolerance
To prevent the “Insufficient Error Handling” Domino Effect, you must build your integrations with the assumption that failure is inevitable. The goal is not to prevent all failures, but to recover from them gracefully.
Implement Smart Retry and Backoff Mechanisms
For transient errors like network timeouts, don’t just fail. Implement a retry mechanism with exponential backoff. This means the integration waits 1 second before the first retry, 2 seconds before the second, 4 before the third, and so on. This gives the downstream system time to recover without overwhelming it.
Use Circuit Breakers and Dead-Letter Queues
A circuit breaker is a pattern that monitors for a high rate of failures. If a downstream system is consistently failing, the circuit breaker “trips” and stops sending traffic to it for a period of time, preventing a cascading failure. For messages that repeatedly fail even after retries (e.g., due to malformed data), move them to a Dead-Letter Queue (DLQ). This isolates the problematic message so it can be manually inspected and corrected without halting the processing of all other valid messages.
Successful system integration is a discipline, not a one-off project. It requires a strategic mindset that prioritizes decoupling, governance, resilience, and ownership. By learning to recognize these common failure patterns and proactively applying these prevention tactics, you can transform your integrations from a source of fragility and risk into a powerful, scalable, and reliable engine for business growth.
Your Next Read:
Get a FREE
Proof of Concept
& Consultation
No Cost, No Commitment!