In the world of digital transformation, automated workflows are the engines of efficiency. They promise to streamline operations, reduce manual effort, and accelerate business processes at a scale humans simply can’t match. From processing customer orders to managing complex data pipelines, automation is the bedrock of the modern enterprise. But what happens when these finely-tuned engines sputter and stall? The unfortunate reality is that automated processes, for all their power, are inherently brittle. An unexpected API response, a malformed data file, or a temporary network outage can bring an entire workflow to a screeching halt.
Without a deliberate strategy, these failures, known as exceptions, can cause chaos. They lead to silent failures where tasks are dropped without a trace, frantic manual interventions by already busy teams, and a gradual erosion of trust in the very automation that was meant to be a solution. The answer isn’t to aim for a mythical, error-free environment. The answer is to plan for failure. A robust Exception Management Framework is not a “nice-to-have” feature; it’s a foundational requirement for building resilient, reliable, and trustworthy automation.
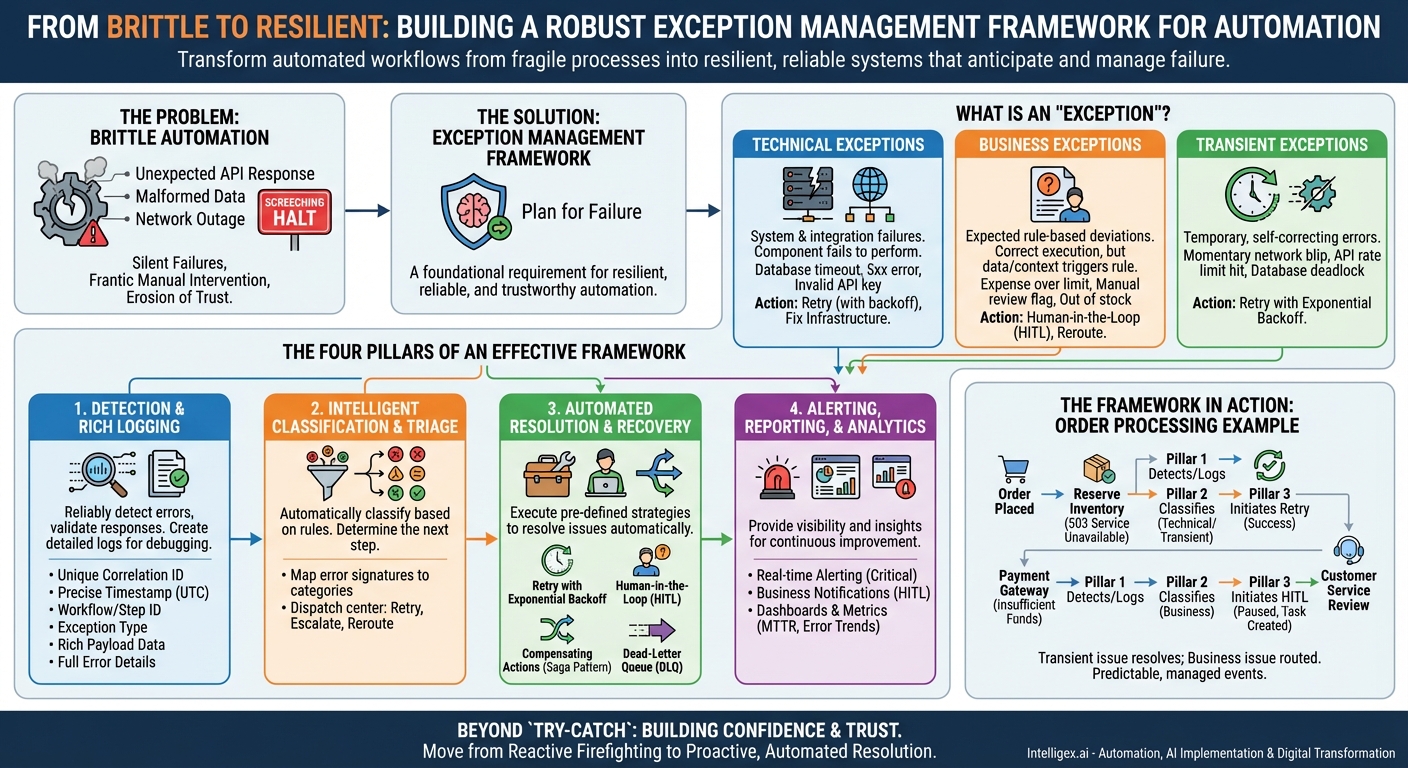
What Exactly Is an “Exception” in Automation?
In the context of automated workflows, an exception is any event or state that disrupts the normal, expected “happy path” of a process. It’s a deviation that the workflow isn’t inherently designed to handle without a specific plan. A mature framework begins by understanding that not all exceptions are created equal. Simply wrapping every step in a generic `try-catch` block is a naive approach that treats a critical system outage the same as a simple data validation issue. To manage exceptions effectively, we must first learn to categorize them.
We can broadly classify exceptions into three main types:
- Technical Exceptions: These are the classic system and integration errors. They occur when a technical component fails to perform its function. Examples include a database connection timing out, a microservice returning a 5xx server error, an invalid API key, or being unable to read a file due to permission issues. These errors are typically outside the control of the business logic itself and point to a problem with the underlying infrastructure or a connected service.
- Business Exceptions: These are not technical failures but rather expected, rule-based deviations from the happy path that require human judgment or a different business process. The workflow has executed correctly from a technical standpoint, but the data or context has triggered a business rule. For instance, an expense report is submitted for an amount exceeding the employee’s automatic approval limit, an insurance claim contains codes that flag it for manual review, or a customer’s order contains an item that is out of stock. The system worked perfectly; it correctly identified a situation that requires a different path.
- Transient Exceptions: This is a critical sub-category of technical exceptions. Transient exceptions are temporary, self-correcting errors. The issue is fleeting, and a subsequent attempt to perform the same action is likely to succeed. Common examples include a momentary network blip, a temporary API rate limit being hit, or a brief database deadlock.
Why is this categorization so vital? Because the response to each type is fundamentally different. You wouldn’t want to retry a business exception five times, and you wouldn’t route a transient network error to a business manager for approval. A solid framework uses this classification to trigger the correct, most efficient resolution strategy automatically.
The Pillars of an Effective Exception Management Framework
A comprehensive framework is a holistic system designed to handle the entire lifecycle of an exception. It’s a strategic blueprint that moves your organization from reactive firefighting to proactive, automated resolution. This framework is built upon four essential pillars that work in concert to create truly resilient systems.
Pillar 1: Detection and Rich Logging
You can’t manage what you can’t see. The first step is to reliably detect that an exception has occurred. This goes beyond just catching errors; it involves proactively validating responses and data at each critical step of a workflow. An API might return an HTTP 200 OK status, but the response body could be empty or malformed—a robust system should detect this discrepancy.
Once an exception is detected, it must be logged with sufficient context to be useful. A simple error message is not enough. A high-quality log entry is the cornerstone of effective debugging and analysis. It should include:
- A Unique Correlation ID: A single identifier that links all log entries for a specific workflow instance, allowing you to trace its journey from start to finish.
- Precise Timestamp: When did the error occur? Using UTC is a best practice for global systems.
- Workflow and Step Identifier: Exactly where in the process did the failure happen?
- Exception Type: The classification (Technical, Business, Transient) determined by the framework.
- Rich Payload Data: The relevant data or message being processed at the time of the error. Care must be taken to sanitize sensitive information (PII, credentials).
- Full Error Details: The complete error message, stack trace, and any relevant error codes (e.g., HTTP status codes).
Pillar 2: Intelligent Classification and Triage
This is where the framework’s intelligence comes into play. Upon detecting and logging an exception, the system must automatically classify it based on predefined rules. This classification engine is the brain of the operation, mapping specific error signatures to the categories we defined earlier.
- An HTTP
503 Service Unavailableis classified as Technical/Transient. - A payment gateway response of
"Card Declined"is a Business Exception. - A
401 Unauthorizederror is a Technical Exception.
Based on this classification, the triage process immediately determines the next step. It’s the dispatch center for exceptions, deciding whether the appropriate action is to retry, escalate, or reroute the workflow without any human intervention.
Pillar 3: Automated Resolution and Recovery Strategies
This pillar is about action. With the exception identified and classified, the framework executes a pre-defined recovery strategy. The goal is to resolve the issue automatically whenever possible, keeping the process moving and minimizing manual effort.
- Retry with Exponential Backoff: The go-to strategy for transient errors. Instead of immediately retrying and potentially overwhelming a struggling service, the framework waits for a short period before the first retry, then a longer period before the second, and so on. Adding “jitter” (a small, random amount of time) to these waits prevents multiple workflow instances from retrying in perfect unison, which can cause a “thundering herd” problem.
- Human-in-the-Loop (HITL): The primary strategy for business exceptions. The workflow is gracefully paused, and the exception, along with all its context, is routed to a human for a decision. This could be a task in a case management system, an item in a dedicated UI, or a ticket in a service desk. Crucially, the workflow should be designed to resume automatically based on the human’s input (e.g., “Approve,” “Reject,” “Reroute”).
- Fail-Gracefully and Compensating Actions: Some processes cannot be paused or retried. If an unrecoverable error occurs midway through a multi-step transaction (like booking a flight and a hotel), the framework should trigger compensating actions to undo the completed steps. This ensures data integrity by, for example, canceling the flight booking if the hotel booking fails. This is often implemented using a Saga pattern.
- Dead-Letter Queue (DLQ): The ultimate safety net. If an exception cannot be resolved after all automated strategies (e.g., it fails all retry attempts), the offending message or task is moved to a DLQ. This prevents a single poison pill message from halting the entire workflow. Engineers can then analyze the contents of the DLQ to diagnose the root cause without impacting ongoing operations.
Pillar 4: Alerting, Reporting, and Analytics
Finally, a great framework provides visibility. It’s not enough to just handle errors; you must learn from them to continuously improve your processes. This pillar focuses on communicating the status of exceptions to the right people and turning error data into actionable insights.
- Real-time Alerting: For critical, system-halting failures (e.g., a persistent failure to connect to a core database), immediate alerts should be sent to the on-call engineering or operations team via tools like PagerDuty or Slack.
- Business Notifications: For business exceptions, notifications should be sent to the relevant business users, directing them to the HITL task queue where their input is needed.
- Dashboards and Reporting: Aggregate exception data into dashboards to track key metrics over time. Visualizing trends like the most frequent error types, the workflow steps with the highest failure rates, and the Mean Time To Resolution (MTTR) provides invaluable feedback for making your automated processes more robust and efficient.
The Framework in Action: An Order Processing Workflow
Let’s see how this works with a tangible example: an automated e-commerce order processing workflow.
An order is placed, and the workflow kicks off. It first needs to call the inventory service to reserve the items. The inventory service, under heavy load, returns an HTTP 503 Service Unavailable error.
- The framework detects and logs the 503 error.
- It classifies this as a Technical/Transient exception.
- The triage process initiates the Retry strategy with exponential backoff. The first retry after 2 seconds fails. The second retry after 4 seconds succeeds. The workflow continues seamlessly. No human intervention was needed.
Next, the workflow calls the payment gateway. The gateway responds successfully, but with a “Insufficient Funds” message.
- The framework detects this specific response.
- It classifies it as a Business Exception.
- The triage process initiates the Human-in-the-Loop strategy. The workflow pauses, and a task is created in the customer service portal with all order details, flagging it for review. A notification is sent to the customer service team.
By applying a structured framework, what could have been a silent failure or a system crash becomes a managed, predictable event. The transient issue resolves itself, and the business issue is routed correctly, all according to a predefined plan.
Beyond `try-catch`: Building for Resilience
Automation holds immense promise, but its true power is only unlocked when it’s built to withstand the imperfections of the real world. An Exception Management Framework is the blueprint for that resilience. It moves your organization from a reactive stance, where errors are crises, to a proactive one, where errors are anticipated and managed automatically.
By thoughtfully implementing the pillars of Detection, Classification, Resolution, and Reporting, you create a virtuous cycle. Your workflows become more reliable, reducing the need for manual intervention. The data and analytics from your framework provide the insights needed to further strengthen your processes. This builds confidence and trust in your automated systems, empowering you to automate more complex, mission-critical processes and achieve the full potential of your digital transformation journey.
Your Next Read:
Category:
Get a FREE
Proof of Concept
& Consultation
No Cost, No Commitment!