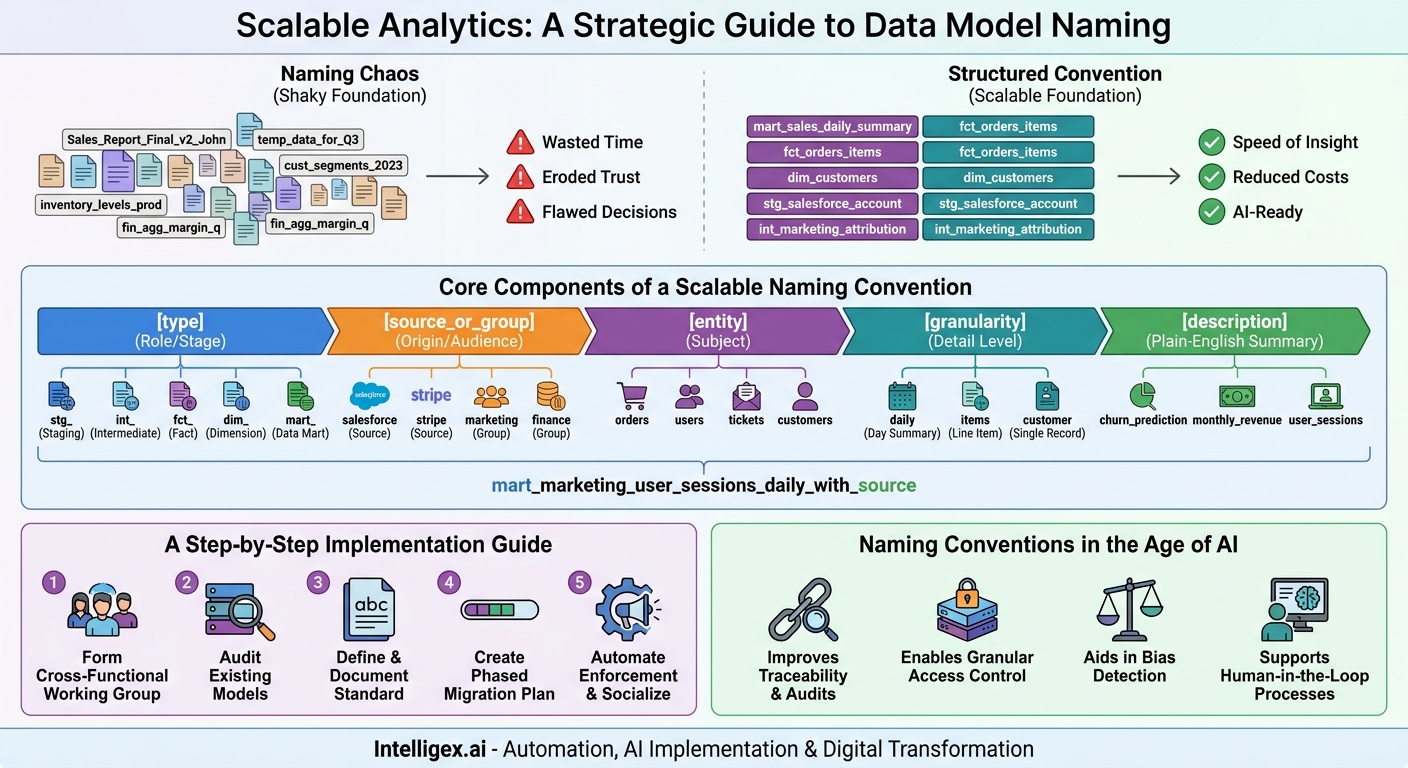
In the rush to become data-driven, many organizations build their analytics infrastructure on a shaky foundation. Data models, the structured datasets that power every dashboard and report, are often created ad-hoc, with names like “Sales_Report_Final_v2_John” or “customer_data_temp_for_Q3.” At first, this seems like a minor inconvenience. But as data volume and complexity grow, these small inconsistencies compound into a massive drag on productivity, trust, and innovation. The problem is not the data itself, but the lack of a shared language to describe it.
A well-defined model naming convention is not corporate bureaucracy. It is a strategic asset. It acts as a universal Rosetta Stone for your data, enabling analysts, data scientists, and business users to find what they need, understand its context, and trust its output without a lengthy investigation. This simple discipline directly impacts your bottom line by increasing the speed of insight, reducing operational costs, and laying a scalable foundation for more advanced analytics, including AI.
The Hidden Costs of Naming Chaos
When data models lack a standardized naming structure, the consequences ripple across the entire organization, creating friction and undermining the value of your data investments. This chaos manifests as wasted time, eroded trust, and flawed decision-making. The impact is felt differently in each department, but the root cause is the same.
Consider these common business scenarios:
- Finance and Sales Misalignment: The finance team pulls a report on quarterly profit margins from a model named
fin_agg_margin_quarterly. At the same time, the sales team presents their performance dashboard, which uses data fromsales_fct_deal_profit_monthly. The numbers don’t match. An urgent, high-stress meeting is called to reconcile the discrepancy, pulling senior leaders and analysts away from their work. The investigation reveals that the two models use slightly different logic for attributing costs. The immediate fire is put out, but a seed of doubt is planted. Leadership now questions the reliability of all financial reporting. - Marketing Campaign Delays: A marketing analyst is tasked with building a campaign targeting high-value customers. Their first step is to find the official, curated list of customer segments. In the data warehouse, they find
cust_segments_2023,user_clusters_v4_final, andmktg_customer_value_tiers. Which one is correct? Which is up-to-date? They spend the first half of their day messaging colleagues, digging through old documentation, and running queries to compare the models. The campaign launch is delayed, and a significant amount of the analyst’s time, which could have been spent on strategic analysis, is lost to simple data discovery. - Supply Chain Breakdowns: An operations manager relies on a dashboard to monitor inventory levels across several warehouses. One morning, the dashboard is broken. The IT team discovers that the underlying data model,
inventory_levels_prod, was deprecated by a data engineering team during a system upgrade. Because there was no clear naming system indicating its downstream dependencies or its replacement (now calledprd_fct_inventory_daily_snapshot), the dashboard connection was not updated. This leads to a temporary black spot in operational visibility, potentially impacting ordering and fulfillment decisions.
In each case, the problem is not a lack of data or talent. It is a lack of clarity. This ambiguity forces your most valuable technical and analytical staff to become data detectives, spending their time on low-value, repetitive tasks instead of driving business outcomes. This directly translates to higher operational costs and a slower pace of business.
Core Components of a Scalable Naming Convention
A robust naming convention is descriptive, predictable, and hierarchical. It tells a story about the data model from left to right, moving from general to specific. While the exact components can be tailored to your organization, a successful structure often includes elements that describe the model’s environment, type, business entity, and granularity.
A good starting point for a model name structure is:
[type]_[source_or_group]_[entity]_[granularity]_[description]
Let’s break down each component:
1. Type: The Model’s Role in the Data Pipeline
This prefix identifies the model’s purpose and its stage in the transformation process. It is the most important component for data engineers and analysts who need to understand the data’s lineage and level of refinement.
- stg_: Staging models. These are typically one-to-one copies of source data, with only light cleaning like casting data types or renaming columns. Example:
stg_salesforce_opportunity. - int_: Intermediate models. These are internal building blocks, not meant for end users. They handle complex transformations or join different sources together before the final output. Example:
int_orders_joined_with_customers. - fct_: Fact models. These models contain business events, transactions, or measurements. They are the core of your analytical datasets, often containing numbers to be aggregated. Example:
fct_invoices. - dim_: Dimension models. These models provide context to the fact models. They describe the “who, what, where, when” of a business event, such as customers, products, or dates. Example:
dim_customers. - mart_: Data marts. These are the final, wide tables designed for a specific business unit or purpose. They join facts and dimensions together and are optimized for reporting and analytics. Example:
mart_finance_profitability.
2. Source or Group: Where the Data Comes From or Who it’s For
This component adds context about the data’s origin or its intended audience. For staging models, this is typically the source system. For data marts, it is the business function.
- Source System:
stg_salesforce_account,stg_stripe_charge. - Business Group:
mart_marketing_campaign_performance,mart_finance_gl_reporting.
3. Entity and Granularity: The What and How Detailed
The entity is the core business subject of the model (e.g., `orders`, `users`, `tickets`). The granularity specifies the level of detail each record represents. Being explicit about granularity prevents common analytical errors, like mixing daily and monthly data.
fct_orders_daily: One record represents the summary of all orders for a single day.fct_order_items: One record represents a single line item within an order.dim_customers: One record represents a single customer.
4. Description: A Plain-English Summary
The final part of the name should be a clear, concise description of the model’s contents or purpose, using full words where possible to avoid ambiguity.
..._churn_prediction_featuresis much clearer than..._churn_feat...._monthly_recurring_revenueis better than..._mrr_summary.
Putting it all together, a name like mart_marketing_user_sessions_daily_with_source is immediately understandable. We know it’s a final model for the marketing team, describing user sessions at a daily level, and includes attribution data about the session source. This clarity accelerates development, simplifies debugging, and builds confidence in the data.
A Step-by-Step Guide to Implementation
Deploying a new naming convention requires more than just writing down the rules. It requires a thoughtful process of consensus-building, planning, and gentle enforcement. Rushing this process can create more confusion than it solves. Follow these steps to ensure a smooth and successful rollout.
- Form a Cross-Functional Working Group. Do not create a naming convention in an IT vacuum. Your most important allies are the people who use the data every day. Assemble a small group with representatives from data engineering, analytics, and key business units like Finance, Marketing, and Operations. This ensures the chosen terminology reflects how the business actually thinks and speaks about itself.
- Audit Your Existing Models. Before you can chart a course, you need to know where you are. Conduct a high-level inventory of your existing data models. You don’t need to analyze every single one. Focus on the most frequently used models and the areas causing the most confusion. Group them into categories (e.g., finance reports, product analytics, sales funnels) to identify patterns of inconsistency.
- Define and Document Your Standard. Using your audit as a guide, have the working group define the components of your naming convention. Debate and decide on the exact terms. Will you use `dim_` or `dimension_`? `customer` or `cust`? Make a decision, and then document it in a single, easily accessible place, like a corporate wiki or your data catalog tool. This document becomes your single source of truth.
- Create a Phased Migration Plan. You cannot and should not try to rename hundreds of existing models overnight. This would break every report and dashboard that depends on them. Instead, create a realistic, phased plan.
- Phase 1 (Immediate): Mandate that all new data models must follow the convention. This stops the bleeding.
- Phase 2 (Next 3-6 months): Identify the 20% of models that cause 80% of the problems (your most critical and most confusing models). Prioritize renaming and updating these, communicating clearly with downstream users.
- Phase 3 (Ongoing): Gradually refactor older, less critical models as they are touched during other project work. Don’t create a special project just to rename old models; it’s rarely worth the effort.
- Automate Enforcement and Socialize the Standard. Make it easy to do the right thing and hard to do the wrong thing. Integrate checks into your development workflow. Tools like SQL linters or dbt pre-commit hooks can automatically flag a model name that doesn’t conform to the standard during code review. Announce the new standard widely, hold short training sessions, and, most importantly, continuously explain the “why” behind the change, focusing on the benefits of speed and clarity for everyone.
Do’s and Don’ts for Effective Naming
As you implement your standard, keep these simple principles in mind. They act as a helpful guardrail to ensure the convention remains clear, useful, and durable.
Do:
- Be Consistent. An imperfect but consistently applied standard is a thousand times better than a perfect standard that no one uses. Consistency is the primary goal.
- Use snake_case. Use all lowercase letters with underscores to separate words (e.g.,
my_model_name). This is the most common convention in SQL and data engineering, ensuring compatibility across different platforms. - Prioritize Clarity Over Brevity. Avoid the temptation to create cryptic abbreviations.
fct_monthly_recurring_revenueis always better thanfct_mrr. A few extra keystrokes save hours of confusion for the next person. - Document Your Definitions. A model name is a great start, but it can’t tell the whole story. Ensure every model has a corresponding description in your data catalog or documentation that defines each column and explains the business logic.
Don’t:
- Use Unpredictable Elements. Never include personal names, dates, or ticket numbers in a model name (e.g.,
sarahs_customer_list_july2024). This signals that the model is temporary and untrustworthy. - Use Special Characters or Spaces. Stick to letters, numbers, and underscores. Hyphens, spaces, and other characters can cause unexpected errors in different databases and tools.
- Use Ambiguous or Overloaded Abbreviations. Does `acct` mean “account” or “accounting”? Does `bal` mean “balance” or “balanced”? If an abbreviation has more than one possible meaning, don’t use it.
- Let the Standard Become Stale. Business changes. Your data models will, too. Revisit your naming convention once a year with the working group to ensure it still meets the needs of the organization.
–
Naming Conventions in the Age of AI
The importance of disciplined naming conventions skyrockets when you introduce AI and machine learning into your analytics ecosystem. An AI model is a black box to most business users. Its recommendations are only trusted if the data feeding it is transparent and well-understood. A clear naming standard is a foundational element of responsible AI governance.
Here’s how it helps:
- Improves Traceability and Audits: When a machine learning model predicts customer churn, auditors and data scientists need to know exactly what data it was trained on. A model built from a feature set named
prd_ml_customer_churn_features_v2is instantly more transparent than one built fromtemp_data_for_model. This traceability is critical for debugging, explaining model behavior, and complying with regulations. - Enables Granular Access Control: Protecting sensitive data is paramount. A good naming convention allows you to implement more effective security policies. For example, you can write a simple rule that restricts access to all models starting with
mart_hr_pii_*to only a specific group of HR managers, ensuring that personally identifiable information is properly firewalled. - Aids in Bias Detection: AI models can inadvertently perpetuate historical biases hidden in data. When the data sources for a model are clearly named, such as
int_loan_applications_with_demographics, it becomes far easier for human reviewers to proactively identify and scrutinize potentially sensitive inputs before they result in a biased outcome. - Supports Human-in-the-Loop Processes: Many AI systems rely on a human to review or approve their decisions. A clear model name gives this human reviewer instant context about the data the AI used, making their oversight faster and more effective.
Your Next Steps to Building a Reliable Data Foundation
Implementing a new naming convention can feel like a daunting project, but it doesn’t have to be. The key is to start small, demonstrate value, and build momentum. You don’t need a six-month project to begin. You just need to take the first step.
In your next team meeting, use this simple action plan to get started:
- Identify one specific pain point. Is it the conflicting sales and finance reports? Or the confusion around marketing attribution? Pick one area where the cost of naming chaos is high and visible.
- Assemble a micro-team. Grab one analyst or business user from that department and one person from the data team.
- Map the core models. Ask them to list the 5-10 most important data models they use to do their job. Write down the current, confusing names.
- Draft a “minimum viable convention.” Together, devise a simple, two or three-part naming structure for just those models. For example,
[type]_[description]might be enough to start. Rename the models on paper and see how much clarity it provides.
This small exercise will demonstrate the value of this approach in a tangible way, creating the buy-in needed to expand the effort. A logical naming convention is more than just a technical best practice. It is a fundamental building block for creating a culture of trust, speed, and confidence in your data. It is the solid ground upon which a truly data-driven enterprise is built.
Your Next Read:
Category:
Get a FREE
Proof of Concept
& Consultation
No Cost, No Commitment!