In the digital-first economy, data is often called the new oil, the lifeblood of an organization. If that’s true, then the data pipeline is the circulatory system—the complex network of arteries and veins responsible for transporting this vital resource from its source to the decision-makers and applications that depend on it. But just like a biological system, a data pipeline can be fragile. A clog, a leak, or a weak point can have catastrophic consequences, leading to flawed business intelligence, malfunctioning machine learning models, and a fundamental loss of trust in the data itself. A pipeline that simply moves data from point A to point B is no longer sufficient. Today’s businesses need pipelines that are not just functional, but demonstrably and consistently reliable.
Building a reliable data pipeline is less about choosing a single, magical tool and more about embracing a disciplined, architectural approach. It involves dissecting the pipeline into its core components and then fortifying each layer with principles of observability, testing, and governance. This is the anatomy of a modern, reliable data pipeline—a system designed not just to work, but to endure, scale, and inspire confidence.
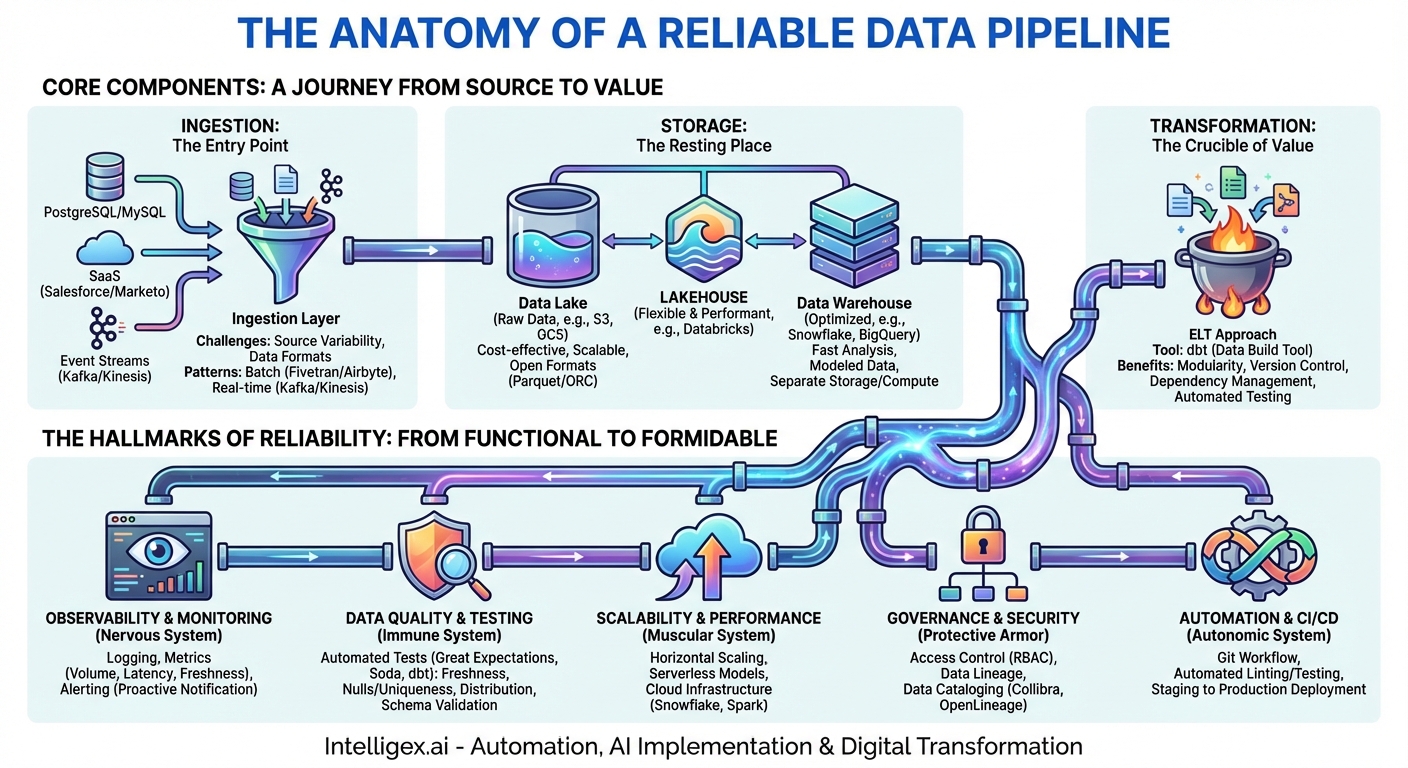
The Core Components: A Journey from Source to Value
At its heart, every data pipeline, whether it’s processing real-time streaming data or nightly batches, follows a fundamental path. Understanding these stages is the first step in identifying potential points of failure and engineering for resilience.
Ingestion: The Entry Point
This is where the data journey begins. Ingestion is the process of extracting data from its various sources, which can range from transactional databases like PostgreSQL and MySQL, to SaaS applications like Salesforce and Marketo, to event streams from user activity on a website. The reliability challenges here are immense.
- Source Variability: Sources can change their schemas without warning (API updates), suffer from downtime, or experience performance degradation. A reliable ingestion layer must be fault-tolerant, capable of handling connection failures with retries and backoff strategies.
- Data Formats: Data arrives in a myriad of formats—structured JSON from an API, semi-structured logs, or binary files. The ingestion process must be robust enough to parse these different formats correctly.
- Ingestion Patterns: The choice between batch, micro-batch, and real-time streaming depends on the use case. A reliable system uses the appropriate pattern. For example, financial transactions demand streaming, whereas a weekly analytics report can use a batch process. Tools like Fivetran and Airbyte excel at batch ingestion from common sources, while technologies like Apache Kafka and AWS Kinesis are the gold standard for streaming.
Storage: The Resting Place
Once ingested, data needs a place to live. The storage layer is no longer just a simple database; it’s a strategic choice that impacts cost, performance, and flexibility. The two primary destinations are the data lake and the data warehouse.
- Data Lakes (e.g., Amazon S3, Google Cloud Storage): These are cost-effective repositories for storing vast amounts of raw, untransformed data in its native format. Their reliability comes from extreme durability and scalability. A key principle for a reliable lake is organization. Storing data in a logical, partitioned format (e.g., by date) and using an open file format like Apache Parquet or ORC is crucial for efficient processing later on.
- Data Warehouses (e.g., Snowflake, BigQuery, Redshift): These are optimized for fast analytical queries. Data here is structured, cleaned, and modeled for business consumption. Modern cloud data warehouses offer incredible reliability by separating storage and compute, allowing each to scale independently. This prevents a large, complex query from impacting data ingestion or other users.
The emerging “Lakehouse” architecture, championed by platforms like Databricks, attempts to merge the benefits of both—the low-cost, flexible storage of a data lake with the performance and transactional guarantees of a data warehouse.
Transformation: The Crucible of Value
Raw data is rarely useful on its own. The transformation stage is where data is cleaned, enriched, aggregated, and modeled into a state that is ready for analysis. This is often the most complex and error-prone part of the pipeline. The modern approach to this is known as ELT (Extract, Load, Transform), where raw data is first loaded into the data warehouse and then transformed using the warehouse’s powerful compute engine.
A tool like dbt (data build tool) has become central to building reliable transformations. It allows data teams to apply software engineering best practices to their SQL-based transformation logic:
- Modularity: Breaking down complex transformations into smaller, reusable SQL models.
- Version Control: Integrating with Git to track changes, collaborate, and perform code reviews.
- Testing: Natively supporting data quality tests on the output of your models.
– Dependency Management: Automatically building a graph (DAG) of your models to ensure they run in the correct order.
Reliability in the transformation layer means ensuring that business logic is correct, consistently applied, and that dependencies between data models are explicitly managed. An error in a single transformation can have a cascading effect, corrupting dozens of downstream tables and reports.
The Hallmarks of Reliability: From Functional to Formidable
Simply having the core components in place isn’t enough. A truly reliable pipeline is wrapped in layers of systems and processes that ensure its health, integrity, and trustworthiness. These are the systems that differentiate a brittle pipeline from a resilient one.
Observability and Monitoring: The Pipeline’s Nervous System
You cannot fix what you cannot see. Observability is the practice of instrumenting your pipeline to provide deep, actionable insights into its state. It goes beyond simple “pass/fail” monitoring.
- Logging: Comprehensive logs from every component provide a detailed, time-stamped record of what happened. When a job fails, well-structured logs are the first place to look for the root cause.
- Metrics: These are quantitative measurements of the pipeline’s performance over time. Key metrics include data volume processed, job duration (latency), records with errors, and data freshness (the time lag between an event happening in the source system and it being available in the warehouse). Dashboards built with tools like Grafana or Datadog can visualize these metrics, making it easy to spot anomalies.
- Alerting: A robust alerting system proactively notifies the on-call team when a metric crosses a critical threshold (e.g., data freshness is older than 60 minutes) or a job fails. This allows for intervention before business users even notice a problem.
Data Quality and Testing: The Immune System
A pipeline can run perfectly on schedule, process a billion rows without error, and still be unreliable if the data it delivers is wrong. Data quality is a non-negotiable aspect of reliability. It involves building an “immune system” that actively detects and quarantines bad data.
This is achieved through automated testing at various stages of the pipeline. Frameworks like Great Expectations, Soda, or the built-in testing features of dbt are essential tools. Common tests include:
- Freshness and Recency Checks: Is the data in this table updated as expected?
- Null/Uniqueness Tests: Is the
user_idcolumn always populated and unique as it should be? - Distributional Checks: Has the average value of
order_totalsuddenly and inexplicably spiked by 300%? This could indicate a currency conversion bug or upstream data corruption. - Schema Validation: Ensure that data columns have not been unexpectedly added, removed, or had their data type changed.
When a data quality test fails, it should ideally halt the downstream pipeline processes to prevent the “garbage” from flowing into production dashboards and models, thus protecting the end users and maintaining their trust.
Scalability and Performance: The Muscular System
A pipeline that works today with 10 million rows must also work tomorrow with 100 million rows. A reliable pipeline is designed for growth. Modern cloud infrastructure makes this more achievable than ever before.
This means choosing tools that can scale horizontally (adding more machines) or that offer serverless models where compute resources are provisioned automatically on demand. Using a cloud data warehouse like Snowflake, which can spin up and down dedicated compute clusters for different workloads, ensures that a heavy transformation job doesn’t slow down the ingestion process. Similarly, using scalable processing engines like Apache Spark or cloud functions for transformation tasks allows the pipeline to handle sudden spikes in data volume without manual intervention.
Governance and Security: The Protective Armor
Reliability also encompasses security and compliance. A pipeline that leaks personally identifiable information (PII) or allows unauthorized access to sensitive data is a failed pipeline. Robust governance provides the protective armor.
- Access Control: Implementing Role-Based Access Control (RBAC) ensures that users and services only have permission to read or write the data they absolutely need.
- Data Lineage: Being able to trace the journey of a data point from its source, through every transformation, to its final destination in a report is critical for debugging, impact analysis, and regulatory compliance (like GDPR). Tools like Collibra or open-source solutions like OpenLineage help map this flow.
- Data Cataloging: A centralized data catalog provides documentation and context for your data assets, making it easier for users to find, understand, and trust the data they are using.
Automation and CI/CD: The Autonomic System
Finally, a reliable pipeline minimizes human error. The best way to do this is through automation. The principles of CI/CD (Continuous Integration/Continuous Deployment), borrowed from software engineering, are now a staple of modern data engineering (often called DataOps).
This means that any change to the pipeline—whether it’s a new transformation, an updated ingestion script, or a new data quality test—should go through an automated workflow:
- The change is made in a separate Git branch.
- A pull request triggers an automated process that runs code linting, syntax checks, and, most importantly, runs the transformations and data quality tests against a staging environment.
- Only after all checks pass can the code be merged and automatically deployed to production.
This process ensures that every change is tested and validated before it can impact the production pipeline, making deployments safer, faster, and more reliable.
Building for the Future: A Holistic Approach
The anatomy of a reliable data pipeline is complex and multifaceted. It is not a single piece of technology, but a living system composed of core components and fortified by layers of observability, testing, security, and automation. Neglecting any one of these areas creates a vulnerability that will inevitably lead to failure.
Viewing the pipeline as an engineered product, rather than a series of ad-hoc scripts, is the fundamental mindset shift required. It demands an investment in a robust architecture and a culture of quality and automation. This investment, however, pays for itself many times over—not just in reduced downtime and fewer firefighting drills for engineers, but in the most valuable currency of all: the unwavering trust of the people who rely on its data to make critical business decisions every single day.
Related Posts
Category:
Get a FREE
Proof of Concept
& Consultation
No Cost, No Commitment!