It’s a scene that plays out in thousands of offices every day. The marketing team pulls a list of “high-engagement leads” for a new campaign, meticulously curating it from their automation platform. At the same time, just one floor down, the sales team is building a pipeline report from their CRM, looking at “active opportunities.” Meanwhile, the customer support team is analyzing ticket data from their helpdesk system to identify “at-risk customers.” All three teams are working diligently, yet they are all, in a sense, looking at different, overlapping, and slightly distorted versions of the same group of people: their customers. This is the quiet, pervasive, and incredibly costly problem of data duplication across teams.
Data duplication isn’t just about having two identical rows in a spreadsheet. It’s a systemic issue where the same core piece of information—be it a customer record, a product detail, or a sales transaction—exists in multiple systems, in multiple formats, and is managed by multiple teams. It’s a data “déjà vu” that creates confusion, erodes trust, and grinds strategic initiatives to a halt. But why does this happen? It’s rarely a single mistake. Instead, data duplication is the natural, almost inevitable byproduct of how modern organizations are structured, how they adopt technology, and the very human behaviors that drive day-to-day work.
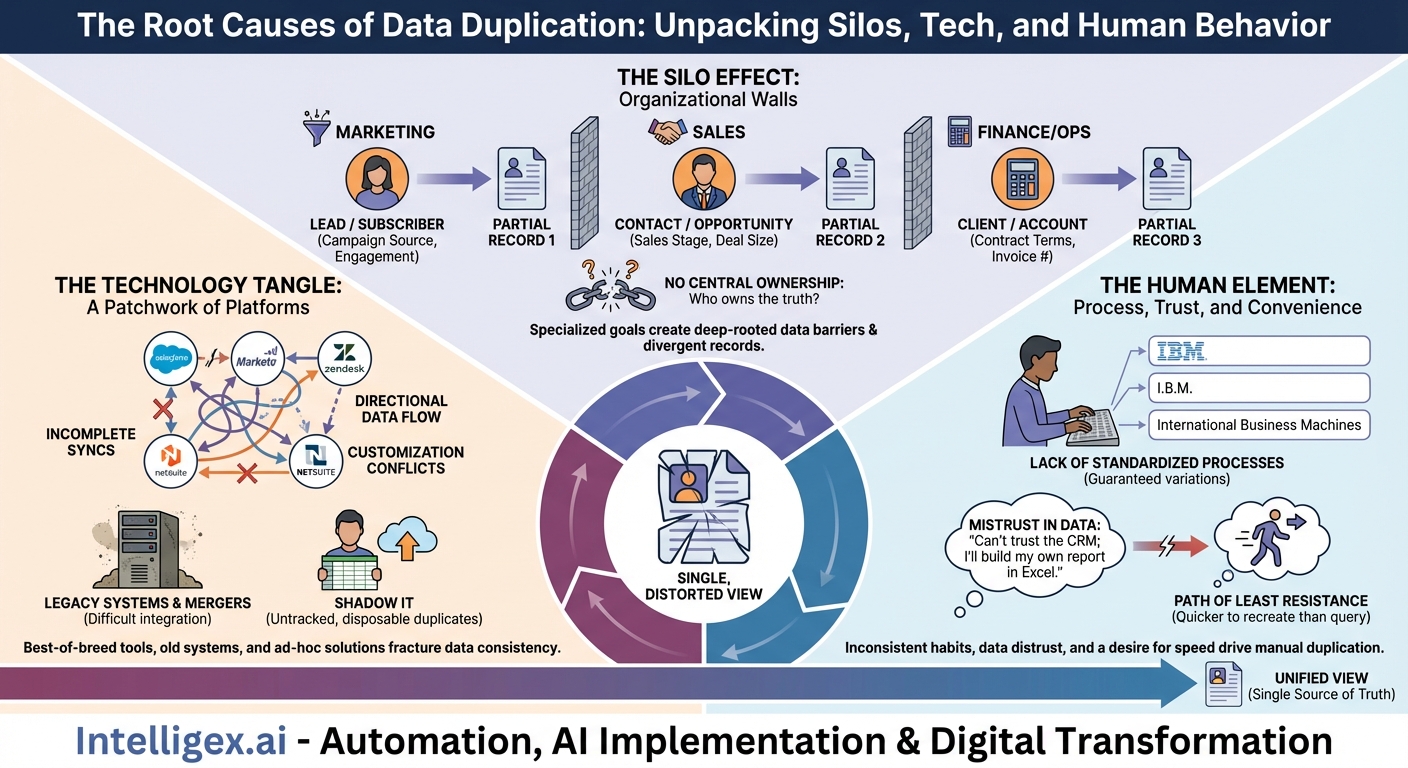
The Silo Effect: When Organizational Walls Become Data Barriers
The primary driver of data duplication is organizational structure. Most companies are built as a collection of specialized departments: Marketing, Sales, Finance, Operations, Support. Each department has its own goals, its own Key Performance Indicators (KPIs), and its own operational cadence. This specialization is efficient for executing specific tasks, but it creates deep-rooted data silos.
Departmental Goals Define the Data
Each team views and defines data through the lens of its own objectives. To the marketing team, a person is a “Lead” or a “Subscriber,” defined by attributes like campaign source, email engagement, and website behavior. Their system is optimized to capture and nurture these data points. Once that person expresses purchase intent, the sales team takes over. In their CRM, that same individual becomes a “Contact” associated with an “Opportunity.” The data that matters now shifts to sales stages, deal size, and close dates. Later, when a deal is closed, the finance team sees them as a “Client” or “Account” in their billing system, defined by contract terms, payment history, and invoice numbers.
While it’s the same person throughout this journey, three distinct data records have been created in three different systems. Each record is a snapshot, a partial truth optimized for a specific department’s function. Without a unifying strategy, these partial truths never merge into a complete, holistic view.
The Void of Central Ownership
This leads to a critical question: who “owns” the customer record? If Marketing, Sales, and Finance all have their own versions, which one is the definitive source of truth? In most organizations, the answer is uncomfortably vague. Without a clear data governance framework or a designated “owner” for critical data entities like “customer” or “product,” a data free-for-all ensues. Each team becomes the de facto owner of its own slice of the data, updating it according to its own processes and priorities. This lack of central stewardship guarantees that records will diverge over time, breeding duplicates and inconsistencies.
The Technology Tangle: A Patchwork of Platforms
Organizational silos are often built upon and reinforced by a fragmented technological landscape. The explosion of specialized Software-as-a-Service (SaaS) tools has empowered departments to choose the “best-of-breed” solution for their specific needs, but this autonomy comes at a steep price for data consistency.
Best-of-Breed Breeds Duplication
A typical enterprise might use Salesforce for sales, Marketo for marketing automation, Zendesk for customer support, and NetSuite for ERP and finance. Each of these platforms is a powerful data repository in its own right. While integrations and APIs exist to connect them, they are rarely a perfect, seamless solution.
- Incomplete Syncs: An integration might only sync a subset of fields, leaving critical context behind in the source system.
- Directional Data Flow: Data might flow one way (e.g., from Marketo to Salesforce) but not the other, meaning updates made in the CRM don’t reflect back in the marketing platform.
- Customization Conflicts: Highly customized fields in one system may have no equivalent in another, preventing them from being synced and forcing users to manually re-enter data.
As a result, each major platform becomes its own “source of truth” for the team that uses it most, creating high-fidelity, high-value duplicates of the same core information across the organization.
Legacy Systems, Mergers, and Shadow IT
The problem is compounded by other technological realities. Many established companies still rely on legacy, on-premise systems that are notoriously difficult to integrate with modern cloud applications. These systems often hold decades of valuable data, but getting it to communicate with the rest of the tech stack is a monumental challenge, forcing teams to manually export and import data, a process ripe for duplication and error.
Mergers and acquisitions are another massive catalyst. When two companies combine, they also combine two entirely separate technology stacks and two distinct data ecosystems. The long, arduous process of consolidating these systems means that for months, or even years, teams operate with parallel, duplicate databases for customers, products, and financials.
Finally, there’s the pervasive issue of “Shadow IT.” A team needs to analyze a specific dataset quickly. Instead of waiting for the official BI team or IT department, they export data into a Google Sheet, upload it to a tool like Airtable, or spin up their own small departmental database. This solves an immediate problem but creates another untracked, unmanaged, and instantly outdated data duplicate that exists outside of any official governance.
The Human Element: Process, Trust, and Convenience
Ultimately, data is created and managed by people. Human behaviors, habits, and perceptions are the final, and perhaps most complex, piece of the data duplication puzzle.
A Lack of Standardized Processes
Without clear, universally enforced rules for data entry, duplication and variation are guaranteed. Consider the simple act of entering a new contact:
- Is the company name “International Business Machines,” “IBM,” or “I.B.M.”?
- Is the state entered as “California,” “CA,” or “Calif.”?
- Is the job title “VP of Sales” or “Vice President, Sales”?
These minor inconsistencies prevent systems from recognizing that these records refer to the same entity. A search for all contacts at “IBM” might miss the other variations, leading a user to believe a contact doesn’t exist and create a new, duplicate entry. This lack of a common “data dictionary” and standardized entry procedures is a primary cause of low-level, high-volume duplication.
Mistrust in the Data
A particularly damaging driver of duplication is a lack of trust. Imagine an analyst on the finance team who needs to report on quarterly revenue by region. They know the sales team’s CRM data is often updated sporadically. A salesperson might not update an opportunity’s status until the end of the week, or they might enter projected close dates that are overly optimistic.
“I can’t trust the CRM for my financial reports. I’ll just pull the raw transaction data from the billing system and build my own regional breakdown in Excel. At least I know *that* data is accurate.”
This sentiment is incredibly common. When one team perceives another’s data as unreliable, incomplete, or out-of-date, their natural reaction is to create their own “trusted” version. They will pull data from what they consider a more reliable source and maintain it separately. This act, born of a desire for accuracy, paradoxically contributes to the overall chaos by creating yet another competing data set, further eroding any chance of a single source of truth.
The Path of Least Resistance
Finally, there is simple human inertia. Finding the authoritative source of data, requesting access, learning how to query it, and waiting for the results often involves more effort than simply recreating the data. It can be faster for a marketing specialist to export a list from their system and manually add a few columns of data from another report than it is to request a formal, integrated view from the IT or data team. People are wired to solve their immediate problems as efficiently as possible, and that path of least resistance often involves creating a quick, disposable, and duplicative data asset.
Breaking the Cycle
Data duplication is not a character flaw of an organization; it’s a systemic condition born from the interplay of organizational structure, technology choices, and human behavior. Silos create the need for separate systems. A fragmented tech stack provides the infrastructure for duplication. And a lack of trust and standardized processes motivates individuals to perpetuate the cycle.
The consequences are severe: conflicting analytics lead to poor business decisions, operational inefficiencies waste countless hours on manual data reconciliation, and a fragmented customer view results in a disjointed and frustrating customer experience. Recognizing these root causes is the first and most critical step. Moving forward requires a conscious, strategic effort to break down these barriers through strong data governance, a commitment to technological integration and master data management, and the fostering of a collaborative culture built on a shared, trusted, and unified view of the organization’s most valuable asset: its data.
Related Posts
Category:
Get a FREE
Proof of Concept
& Consultation
No Cost, No Commitment!